本项目仓库地址:https://github.com/zsq259/RISC-V。
一级流水
RISC-V 模拟器是一个用 c++ 模拟 cpu 来实现 RV32I 指令集的 PPCA 大作业。本文将从 0 开始介绍作者在 PPCA 期间对此的实现。
这个作业,以我目前的认识来说,就是用 c++ 代码去模拟一个 cpu,接受一系列的指令(输入数据)然后大模拟,再返回数据。
由于模拟的是 cpu 的硬件,所以首先需要了解 cpu 的硬件架构,可以参考 计算机科学速成课 的第五集到第九集。也可以参考速成课的速通笔记。
然后就可以去看 RV32I 的指令集了(反正我是这个顺序)。这里感谢 crm 已经整理了部分需要的指令集**这里,同时也可以在线查找这里**。
当然,一开始看到这个表的时候我是一脸懵的,完全看不懂,所以这里解释一下:

首先这张图表面了六大类指令的格式。最上方的数字是32位二进制数的位置。 opcode 表示指令的大类,rd 表示 目标寄存器,funct3 和 funct7 表示在大类里面细分时的依据,rs1 和 rs2 则是作为参数的寄存器,imm 表示立即数,imm[4:1] 表示32位二进制数的这几位所对应的是立即数的第4位到第1位。是的,可以发现立即数被拆成了好几个部分,相当于还要在解码的时候再拼起来。我尝试搜索了其原因,但是以我现在的知识无法理解。
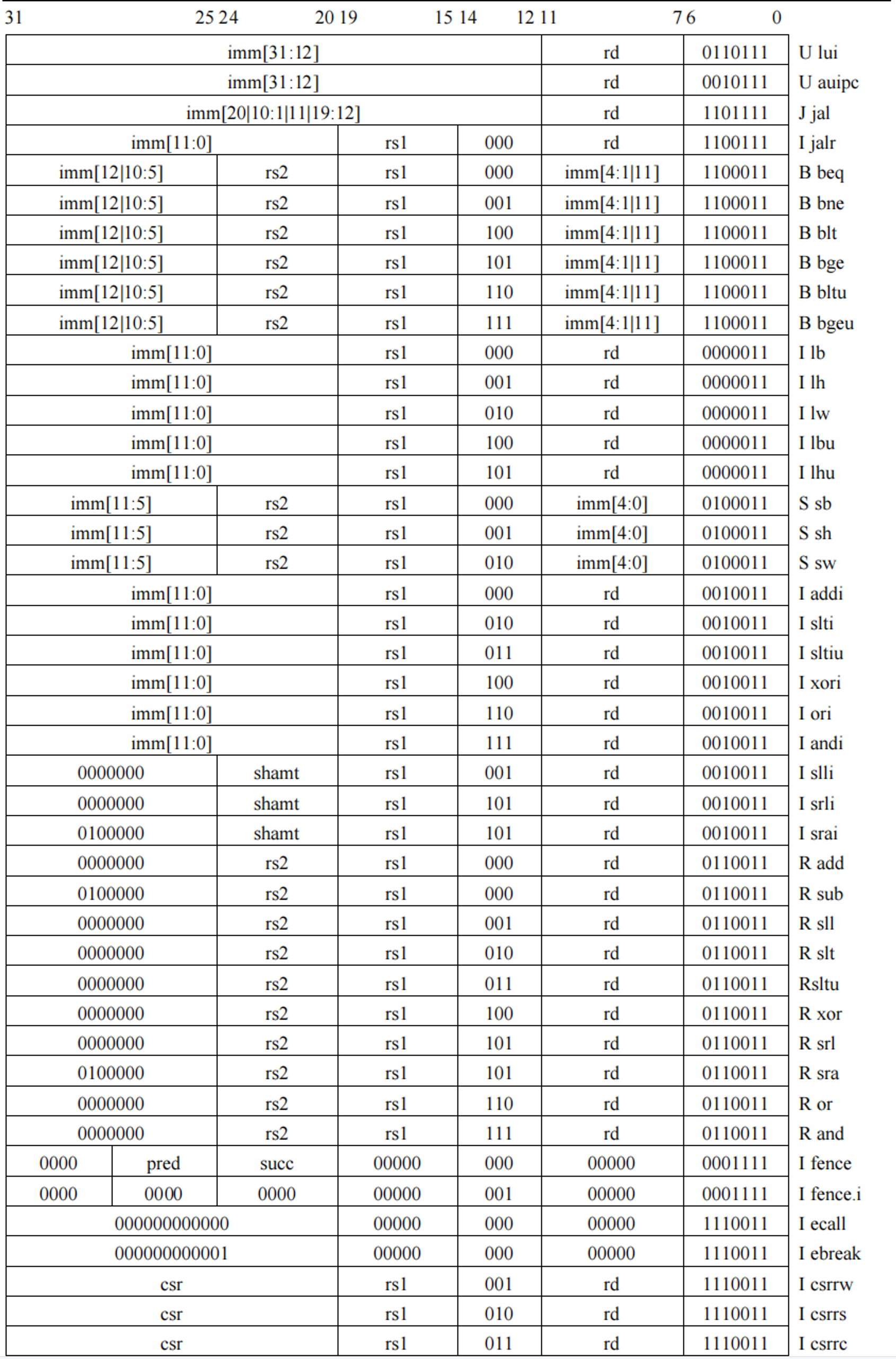
然后这张图就是所有指令的参数了。同时类似于 imm[12|10:5] 则是表示立即数的 12 位以及 10 位到 5 位,没错还是奇怪的拆开。
而对于每个指令的具体操作,上面给出的参考链接里已经有了一部分解释。而似乎更全的解释在 RISC-V 手册的附录可以查找。
以及,更普遍地能看到的一种描述指令的方式其实是,比如 add x1 x2 x3,这里 rd 是最前面的,rs1 和 rs2 是后面的两个。似乎默认的都是这样写的,我也不清楚为什么。
在了解指令后,让我们把目光放到输入数据上(面向数据(雾)):
#include "io.inc"
int main() {
printInt(177);
return judgeResult; // 94
}
这是 sample.c,是编译之前的源代码。~~实际上我们并不用管它。~~最后 return 后的注释则是我们需要输出的结果。
@00000000
37 01 02 00 EF 10 00 04 13 05 F0 0F B7 06 03 00
23 82 A6 00 6F F0 9F FF
@00001000
37 17 00 00 83 27 C7 06 33 45 F5 00 13 05 D5 0A
23 26 A7 06 67 80 00 00 83 47 05 00 63 82 07 02
37 17 00 00 83 26 C7 06 B3 C7 D7 00 93 87 97 20
23 26 F7 06 13 05 15 00 83 47 05 00 E3 94 07 FE
67 80 00 00 13 01 01 FF 23 26 11 00 13 05 10 0B
EF F0 1F FB B7 17 00 00 03 A5 C7 06 83 20 C1 00
13 01 01 01 67 80 00 00
@00001068
FD 00 00 00
这是下发的 sample.data。而在我们实现的时候,我们是先直接把它全部读入到我们模拟的内存中。@00000000意味着内存中的地址。后面的十六进制数则是指令。每次读四个,前面读进来的其实是二进制数的低位,然后再解码成指令。
./test/test.om: file format elf32-littleriscv
Disassembly of section .rom:
00000000 <.rom>:
0: 00020137 lui sp,0x20
4: 040010ef jal ra,1044 <main>
8: 0ff00513 li a0,255
c: 000306b7 lui a3,0x30
10: 00a68223 sb a0,4(a3) # 30004 <__heap_start+0x2e004>
14: ff9ff06f j c <printInt-0xff4>
Disassembly of section .text:
00001000 <printInt>:
1000: 00001737 lui a4,0x1
1004: 06c72783 lw a5,108(a4) # 106c <__bss_end>
1008: 00f54533 xor a0,a0,a5
100c: 0ad50513 addi a0,a0,173
1010: 06a72623 sw a0,108(a4)
1014: 00008067 ret
00001018 <printStr>:
1018: 00054783 lbu a5,0(a0)
101c: 02078263 beqz a5,1040 <printStr+0x28>
1020: 00001737 lui a4,0x1
1024: 06c72683 lw a3,108(a4) # 106c <__bss_end>
1028: 00d7c7b3 xor a5,a5,a3
102c: 20978793 addi a5,a5,521
1030: 06f72623 sw a5,108(a4)
1034: 00150513 addi a0,a0,1
1038: 00054783 lbu a5,0(a0)
103c: fe0794e3 bnez a5,1024 <printStr+0xc>
1040: 00008067 ret
00001044 <main>:
1044: ff010113 addi sp,sp,-16 # 1fff0 <__heap_start+0x1dff0>
1048: 00112623 sw ra,12(sp)
104c: 0b100513 li a0,177
1050: fb1ff0ef jal ra,1000 <printInt>
1054: 000017b7 lui a5,0x1
1058: 06c7a503 lw a0,108(a5) # 106c <__bss_end>
105c: 00c12083 lw ra,12(sp)
1060: 01010113 addi sp,sp,16
1064: 00008067 ret
Disassembly of section .srodata:
00001068 <Mod>:
1068: 00fd addi ra,ra,31
...
Disassembly of section .sbss:
0000106c <judgeResult>:
106c: 0000 unimp
...
Disassembly of section .comment:
00000000 <.comment>:
0: 3a434347 fmsub.d ft6,ft6,ft4,ft7,rmm
4: 2820 fld fs0,80(s0)
6: 29554e47 fmsub.s ft8,fa0,fs5,ft5,rmm
a: 3820 fld fs0,112(s0)
c: 332e fld ft6,232(sp)
e: 302e fld ft0,232(sp)
...
这是 sample.dump,可以说是对上面输入的解释,第一列代表内存的位置,后面可以清楚的看到对应的指令和参数。当然有一些细节部分我也没有深入追究。
细心的读者可能会发现,在 .dump 文件中,关于指令的名称和操作数似乎有一些令人迷惑的地方。首先,这是因为有一些指令实际上是等价于另外一些指令的。比如说,beqz 这个指令在表中就没有出现过,而它就等价于 beq 的一个寄存器为 x0,再与另一个寄存器的值比较。bnez 也是同理。除此之外,还有 li,ret等,具体也可以参考 RISC-V 手册。其次,一个小小的细节是 .dump 文件中的操作数使用的是寄存器的别名,比如说 sp,a0等等,关于这个也可以去看 crm的笔记。
当我们掌握所有的指令后,我们就可以动手写一个一级流水的笨蛋模拟器了。用 c++ 模拟各个硬件,处理每个指令即可。当然,还有一些小小的细节值得注意(我自己写的时候遇到的):
- 对于那些会改变 pc 的指令,如果触发了 pc 的跳转,那么就不会再自动 pc+4 了。
x0寄存器的值永远都是 0,哪怕有指令试图将其改变也是无效的。- 注意小端序和大端序的区分。
到此,至少本人已经用一级流水能跑模拟器了。(虽说模拟地并不完全并且第一次提交的时候忘记删debug输出导致stdout挤爆了然后oj炸了)
当然,写一个一级流水的模拟器并不是必要的,并且对于接下来马上提到的 Tomasulo 算法而言似乎并不能很好地进行代码复用。(或许还是可以作为辅助调试的方法吧(雾))
Tomasulo
当然,光有笨蛋的一级流水可是不行的呐,毕竟有些情况下性能会比较低。比如说以下情况:
add x1 x2 x3
sub x10 x1 x4
add x5 x6 x7
那么当第一行的指令在执行的时候,理论上第三行的指令是完全不受影响的,但是还是得老实等在那,被卡住了。所以,之后要了解的 Tomasulo 算法便是能够乱序执行以提高效率的手段。
在进一步了解 Tomasulo 之前,让我们回顾一个概念:时钟周期。回头看一下我们的一级流水,我们会发现其实它并没有太与时钟周期挂钩,因为一直都是读入指令->解析指令->处理指令来驱动的。但是 Tomasulo 则不然,其后将提到的各个元件和乱序执行等将会以及作业要求提高我们对于时钟周期的要求。因此在处理之前把这个问题理清楚是有必要的。
时钟周期
我们知道,cpu 里实际上是以时钟来驱动运行的。在一个时钟内,各个元件都并行地进行“一步”操作。当然,在我们这个作业中也不需要更加细致地深入了解其物理原理和硬件实现。但是由于 c++ 模拟只能串行不能并行,所以对于时钟的模拟显得比较抽象nitian。具体来说,我们设一个变量 clock 代表时钟,然后每过一个周期就 clock++ 已经开始抽象了。那么在我们手动增加 clock 的间隔中,便可以认为其中运行的程序都是在一个周期内并行的。这也意味着在一个时钟周期内其中运行的元件可以以任意顺序执行。
要实现这一点的话,一个简单而泥潭的方法是对于每个通用寄存器(可以理解为所有东西)都存一个当前的状态和下一时刻的状态,然后再在每个周期末将“下一时刻”更新至“当前时刻”。
而对于一个时钟周期内具体能干什么事情,则是一个更加抽象nitian的问题。 我目前了解到的也比较模糊。目前有(有些涉及到具体的元件目前还没讲):
- fetch (取指令)需一个周期
- decode (解码)需一个周期
- issue (发射) 可以和 decode 在一个周期一起进行也可以分开
- 在 reservation station 里,一个周期内能执行的指令取决于 ALU 的个数(如果ALU足够多可以全执行)
思想
让我们回到 Tomasulo 上来,在上面的例子中,第三行的 add 明显是可以在第一行的指令执行的同时执行的(如果有多个 ALU 并行的话),但是第二行的 sub 必须等第一行执行完后才能执行,否则会有 RAW(read after write) 问题。那么这里就体现了一些依赖关系,某些指令必须在一些指令之后执行。而这个关系能够比较自然地让我们联想到拓扑序。实际上,Tomasulo 采取的也是类似的方法:记录每个指令所依赖的指令,待其依赖的指令执行完毕,操作数准备好之后再执行。
同时,Tomasulo 还有一个概念:寄存器重命名。这是一种类似于缓存的思想。在前面的一级流水中,我们是在处理指令的时候,直接在寄存器上操作。但是,当一条指令的操作数所需的寄存器没有被占用时,我们可以直接将操作数取出来并存放起来,这样这条指令就与其操作数所需的寄存器没有关系了。在之后的 Reservation station 部分,我们将详细讨论这一部分。
架构
我的 Tomasulo 的架构参考的是 Computer Architecture:A Quantitative Approach(计算机体系结构:量化研究方法)第 3.4 章到第 3.6 章的内容,并加上个人的理解魔改。以下是架构图:
接下来将对各个元件进行介绍。
Instruction unit
这个部分从内存取出指令(fetch),进行解码(decode)再发射(issue)到 RoB。没什么好说的
Reservation Station(保留站 RS)
前面提到了 Tomasulo 的思想是根据依赖来执行指令和寄存器重命名。在保留站中我们将看到它具体的工作。首先,(我的)保留站的一个元素有以下内容:
- busy:在执行 or 执行完毕
- op:指令类型
- vj:第一个操作数
- vk:第二个操作数
- qj:第一个操作数所在的寄存器依赖的指令在 RoB (之后会提到)中的编号,如果为 0 说明无依赖可以执行
- qk:第二个操作数所在的寄存器依赖的指令在 RoB 中的编号(同 qj)
- dest:这条指令在 RoB 中对应的位置
而 RS 实际上是一个类似于表格的形式:
| busy | op | vj | vk | qj | qk | dest |
|---|---|---|---|---|---|---|
由于没有例子我就不往里面填东西了
而在这些元素中,值得关注的就是 vj, vk 和 qj, qk。首先看到 vj, vk,它们就相当于寄存器重命名,把本来在寄存器中的操作数存在了 RS 中。这样一来,这条指令在读完操作数后就与寄存器没有关系了。而 qj, qk 则维护了指令操作数所在的寄存器的依赖关系。当 qj, qk 均为 0 的时候,代表这条指令已经没有依赖,操作数准备完毕,可以执行了。反之,则意味着对应的寄存器在前面还有指令尚未执行完毕,因此需要等待。而此时 qj, qk 则就设置为 占用对应寄存器的指令在 RoB 中的编号。而什么时候获得这个值呢?我们将在后面 RoB 的部分提到。
Register File
这个也被称为 qi,记录的是某一寄存器目前是被 RoB 中的哪个指令占用的,能够使 RS 获得 qj, qk。
Load and Store Buffer
如果熟悉指令的话,我们会发现有两类指令load和store的特点是要依靠内存操作。这就不像寄存器一样可以记录依赖了,毕竟内存那么大嘛。而且读写内存也是连续的几个字节。所以对于这两类指令,一种可能的做法是,使这两种指令顺序执行。稍微优化一点的话,可以发现如果 load指令前没有 store 指令的话就可以执行了,而 store 指令前面必须没有 load 或 store 指令才能执行。基于这种特性,我们能够提出一种更加简单的架构。但是我摆了所以如果有机会再改或者介绍
Reorder Buffer(重排序缓冲区 RoB)
可以先思考一下,光有前面的结构,是不是也能跑了?答案是是的。
但是存在一个问题,当遇到条件跳转指令的时候,由于乱序执行,必须等条件跳转指令所需的寄存器依赖消除后,才能继续计算应该跳转的分支。所以在此之前 fetch 和 decode 都会停止。这自然是不太优雅的。因此一个可能的手段是分支预测。预测的方式将在后面介绍。但是分支预测又会带来一个问题:预测错误之后的补救。如果每条指令都是直接修改寄存器的值的话,在预测错误后执行的那些指令带来的影响将难以消除。因此,我们有了 RoB。正如其名字,它将乱序执行后的指令重新按照发射的顺序排序。它使用了循环队列的结构,也就意味着先进先出。在指令发射后,它就进入 RoB。在执行完后,指令并不直接修改寄存器,而是将指令需要修改的寄存器编号(或内存位置)(dest)和对应的值(value)记录在 RoB 中。而每个周期检测队首的指令是否已经执行完毕,如果执行完毕的话,就按照记录修改寄存器或内存,这一过程也称为提交(commit)。这样一来,乱序执行完毕后的结果将按照顺序来修改寄存器。
而在上文提到的寄存器依赖中,当新发射的指令依赖的寄存器被某个已经执行完毕的指令占用,却还没有在队首被提交的话,那么这时就直接从 RoB 中获取所需的操作数即可。
分支预测器
可以参考wikipedia上的分支预测器介绍。
我的实现是,对 pc 取6位进行 hash (3到8位),再对 hash 的值使用四级自适应预测器,再在里面套一层二位饱和预测器。具体的实现方式可以看 wiki,也比较简单,这里就不详细展开。
一些细节
对于 pc 指针的移动是一个需要注意的地方,稍有不慎, fetch 和 decode 就会乱掉。这里稍微讨论一下我的实现。
首先,需要更改 pc 的值的指令有 B 型指令,J 型指令和 jail 指令。同时,正常情况下 pc 会自动 +4。那么同样地,在不正常的情况下,如指令发射失败,也是需要注意的地方。以及,在第一个周期,只有 fetch 指令运行而没有 decode 也是需要注意的地方。
对于 B 和 J 型指令,我们在解码之后立即能得到 pc 需要跳转的位置(B 型通过预测),但同一周期 fetch 到的指令则是无效的。因此在下一个周期 decode 的时候处理的指令也是无效的,需要跳过。
而对于 jail ,pc 之后要跳转的位置是难以预测的所以就不预测了。因此,在 jail commit 之前,fetch 和 decode 都需要停掉,一直等到计算出需要跳转的位置为止。
对于发射失败而言,下一个周期需要继续发射这条指令。更优化的方法是采取 instruction queue 和 多发射的手段来解决这个问题,但是那需要更深入的理解摆了,因此这里讨论的是一种比较粗暴的方法。
在简单分析了这几种情况之后,就可以开始具体的讨论了。首先,在正常情况下,pc 会自动 +4 的操作似乎有两种选择,一种是在 fetch 之后,另一种则是在 decode 之后。由于第一个周期没有 decode ,因此我选择的是第一种。(事实上我不清楚真正的架构是如何实现的)
现在来看,对于 B 和 J ,似乎没有停掉 fetch 的必要。下个周期的 fetch 能够直接从修改后的 pc 处读入。但是下个周期的 decode 则是需要中断,因为指令失效了。对于 jalr 则是整个都中断了。对于发射失败的话,下个周期 decode 则是继续发射这个周期的指令,而下个周期的 fetch 就要停掉。但是注意到,这个周期的 fetch 已经读入下个周期需要 decode 的指令了,这个指令则需要延后在我这里就是失效了。而由于要求硬件并行,也就是 c++模拟时各个函数可以乱序执行,那则是有可能在 decode 之后才执行 fetch ,所以并不能直接在 decode 里面直接改下一个周期的指令,而是需要置一个 tag 表示下个周期的指令应该修改。
感谢
感谢 DarkShrapness ,Wankupi 等人的帮助,对于我对这个作业的理解和思考提供了很大的帮助。


